
![Amazing Tweets From Space dell'astronauta Chris Hadfield [Organizzato]](https://gadget-info.com/img/more-stuff/858/astronaut-chris-hadfield-s-amazing-tweets-from-space.jpg)

Evidentemente, la percettibilità degli esseri umani e un dispositivo elettronico come un computer sono diversi. Gli umani possono capire qualsiasi cosa attraverso i linguaggi naturali, ma un computer no. Il computer ha bisogno di un traduttore per convertire le lingue scritte nella forma leggibile dall'uomo in una forma leggibile dal computer.
Compilatore e interprete sono i tipi di traduttore linguistico. Cos'è il traduttore di lingua? Questa domanda potrebbe sorgere nella tua mente.
Un traduttore linguistico è un software che traduce i programmi da una lingua di origine che sono in una forma leggibile in un programma equivalente in un linguaggio di oggetti. La lingua di origine è generalmente un linguaggio di programmazione di alto livello e la lingua dell'oggetto è in genere la lingua macchina di un computer reale.
Grafico comparativo
| Base per il confronto | Compiler | Interprete |
|---|---|---|
| Ingresso | Ci vuole un intero programma alla volta. | Prende una singola riga di codice o istruzione alla volta. |
| Produzione | Genera codice oggetto intermedio. | Non produce alcun codice oggetto intermedio. |
| Meccanismo di lavoro | La compilazione viene eseguita prima dell'esecuzione. | La compilazione e l'esecuzione avvengono contemporaneamente. |
| Velocità | Comparativamente più veloce | Più lentamente |
| Memoria | Il requisito di memoria è più dovuto alla creazione del codice oggetto. | Richiede meno memoria in quanto non crea codice oggetto intermedio. |
| Errori | Mostra tutti gli errori dopo la compilazione, tutti allo stesso tempo. | Visualizza l'errore di ogni riga uno per uno. |
| Rilevamento degli errori | Difficile | Più facile in confronto |
| Relativi linguaggi di programmazione | C, C ++, C #, Scala, dattiloscritto usa il compilatore. | Java, PHP, Perl, Python, Ruby utilizza un interprete. |
Definizione del compilatore
Un compilatore è un programma che legge un programma scritto nella lingua di alto livello e lo converte nella macchina o nella lingua di basso livello e segnala gli errori presenti nel programma. Converte l'intero codice sorgente in un colpo solo o potrebbe richiedere più passaggi per farlo, ma alla fine l'utente ottiene il codice compilato che è pronto per essere eseguito.

Il compilatore funziona su fasi; varie fasi possono essere raggruppate in due parti che sono:
- Analisi La fase del compilatore viene anche definita come il front-end in cui il programma è diviso in parti costituenti fondamentali e controlla la grammatica, la semantica e la sintassi del codice dopo il quale viene generato il codice intermedio. La fase di analisi include analizzatore lessicale, analizzatore semantico e analizzatore di sintassi.
- La fase di sintesi del compilatore è anche nota come back-end in cui il codice intermedio è ottimizzato e viene generato il codice di destinazione. La fase di sintesi include ottimizzatore di codice e generatore di codice.
FASI DEL COMPILATORE
Ora capiamo il funzionamento di ogni fase in dettaglio.
- Analizzatore lessicale : analizza il codice come un flusso di caratteri, raggruppa la sequenza di caratteri in lessemi e genera una sequenza di token con riferimento al linguaggio di programmazione.
- Sintassi Analyzer : in questa fase, i token generati nella fase precedente vengono confrontati con la grammatica del linguaggio di programmazione, indipendentemente dal fatto che le espressioni siano sintatticamente corrette o meno. Rende gli alberi parse per farlo.
- Semantic Analyzer : verifica se le espressioni e le istruzioni generate nella fase precedente seguono la regola del linguaggio di programmazione o meno e crea alberi di analisi annotati.
- Generatore di codice intermedio : genera un codice intermedio equivalente del codice sorgente. Ci sono molte rappresentazioni del codice intermedio, ma il TAC (Three Address Code) è il più utilizzato.
- Code Optimizer : migliora il tempo e lo spazio richiesto dal programma. Per fare ciò, elimina il codice ridondante presente nel programma.
- Generatore di codice : questa è la fase finale del compilatore in cui viene generato il codice di destinazione per una particolare macchina. Esegue operazioni come la gestione della memoria, l'assegnazione del registro e l'ottimizzazione specifica della macchina.
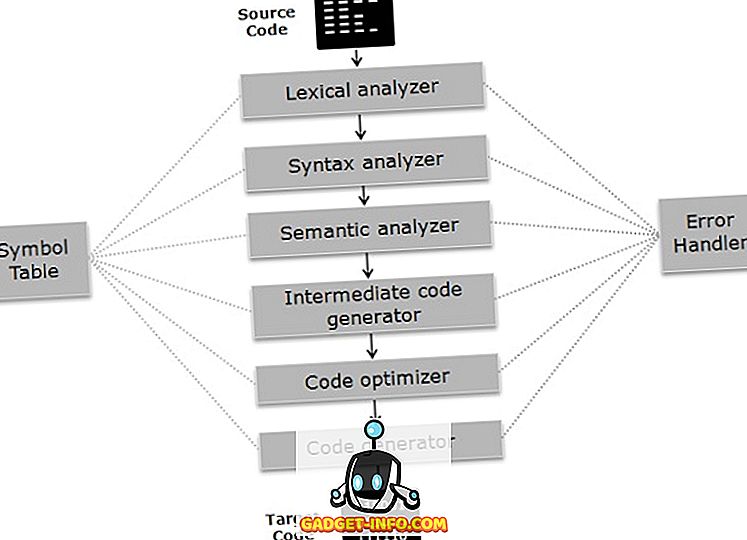
La tabella dei simboli è in qualche modo una struttura dati che gestisce gli identificatori insieme al tipo di dati rilevanti che sta memorizzando. Error Handler rileva, segnala, corregge gli errori incontrati tra le diverse fasi di un compilatore.
Definizione di interprete
L'interprete è un'alternativa per l'implementazione di un linguaggio di programmazione e fa lo stesso lavoro di un compilatore. L'interprete esegue lexing, analisi e controllo del tipo simile a un compilatore. Ma l'interprete elabora l'albero della sintassi direttamente per accedere alle espressioni ed eseguire l'istruzione piuttosto che generare codice dall'albero della sintassi.
Un interprete potrebbe richiedere l'elaborazione dello stesso albero di sintassi più di una volta, motivo per cui l'interpretazione è relativamente più lenta dell'esecuzione del programma compilato.
Compilazione e interpretazione probabilmente si combinano per implementare un linguaggio di programmazione. In cui un compilatore genera codice di livello intermedio, il codice viene interpretato anziché compilato in codice macchina.
L'utilizzo di un interprete è vantaggioso durante lo sviluppo del programma, in cui la parte più importante consiste nel poter testare rapidamente una modifica del programma piuttosto che eseguire il programma in modo efficiente.
Differenze chiave tra compilatore e interprete
Diamo un'occhiata alle principali differenze tra compilatore e interprete.
- Il compilatore prende un programma nel suo complesso e lo traduce, ma l'interprete traduce una dichiarazione di programma per istruzione.
- Codice intermedio o codice obiettivo generato in caso di compilatore. Come contro interprete non crea codice intermedio.
- Un compilatore è comparativamente più veloce dell'interprete in quanto il compilatore prende tutto il programma in una volta sola, mentre gli interpreti compilano ogni riga di codice dopo l'altra.
- Il compilatore richiede più memoria dell'interprete a causa della generazione del codice oggetto.
- Il compilatore presenta tutti gli errori contemporaneamente ed è difficile rilevare gli errori nell'interpretazione dell'esecutore di contrasto di ciascuna istruzione uno per uno ed è più facile rilevare gli errori.
- Nel compilatore quando si verifica un errore nel programma, interrompe la sua traduzione e dopo aver rimosso l'errore, l'intero programma viene nuovamente tradotto. Al contrario, quando si verifica un errore nell'interprete, impedisce la sua traduzione e dopo aver rimosso l'errore, la traduzione riprende.
- In un compilatore, il processo richiede due passaggi in cui in primo luogo il codice sorgente viene tradotto nel programma di destinazione, quindi eseguito. Mentre sei in Interprete è un processo in un'unica fase in cui il codice sorgente viene compilato ed eseguito nello stesso momento.
- Il compilatore è usato in linguaggi di programmazione come C, C ++, C #, Scala, ecc. Nell'altro Interprete è impiegato in linguaggi come Java, PHP, Ruby, Python, ecc.
Conclusione
Sia il compilatore che l'interprete intendono eseguire lo stesso lavoro, ma differiscono nella procedura operativa, il compilatore prende il codice sorgente in modo aggregato mentre l'interprete prende parti costitutive del codice sorgente, vale a dire, dichiarazione per dichiarazione.
Sebbene sia il compilatore che l'interprete hanno alcuni vantaggi e svantaggi, come i linguaggi interpretati sono considerati come multipiattaforma, cioè il codice è portatile. Inoltre, non ha bisogno di compilare istruzioni in precedenza, diversamente dal compilatore, che risparmia tempo. Le lingue compilate sono più veloci per quanto riguarda il processo di compilazione.






